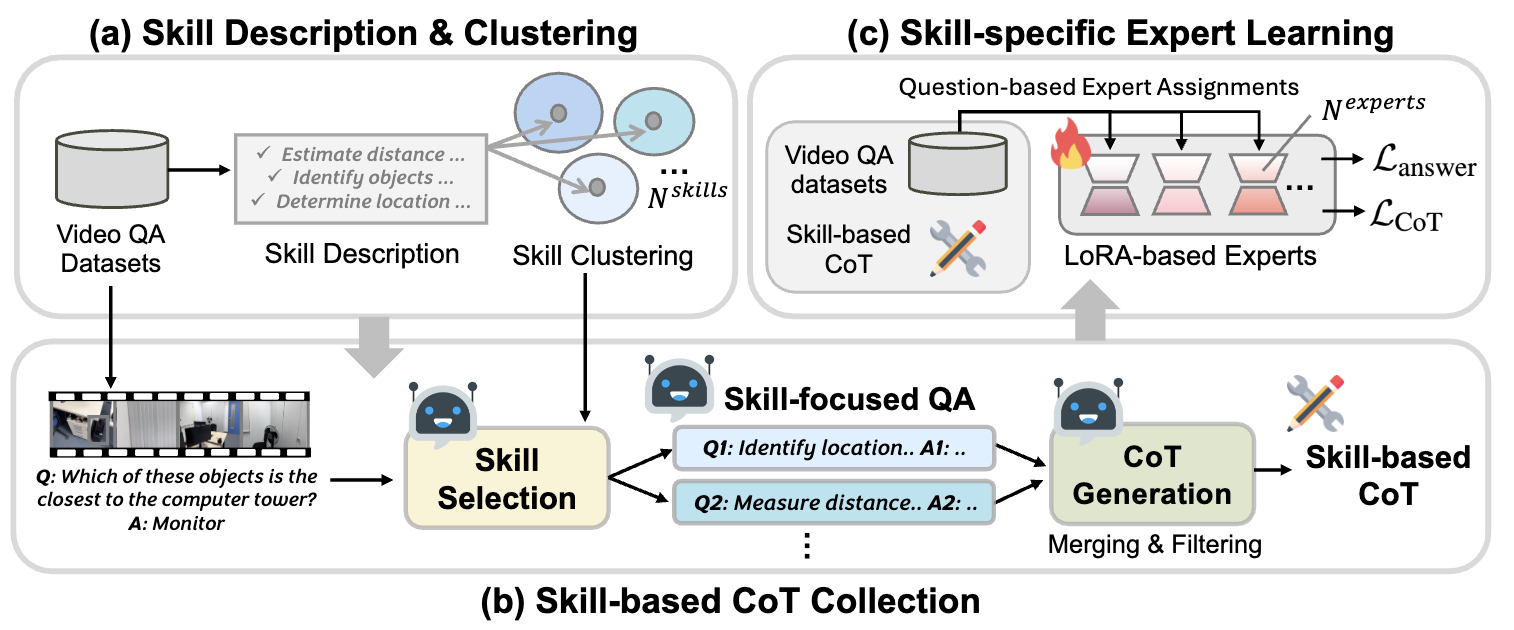
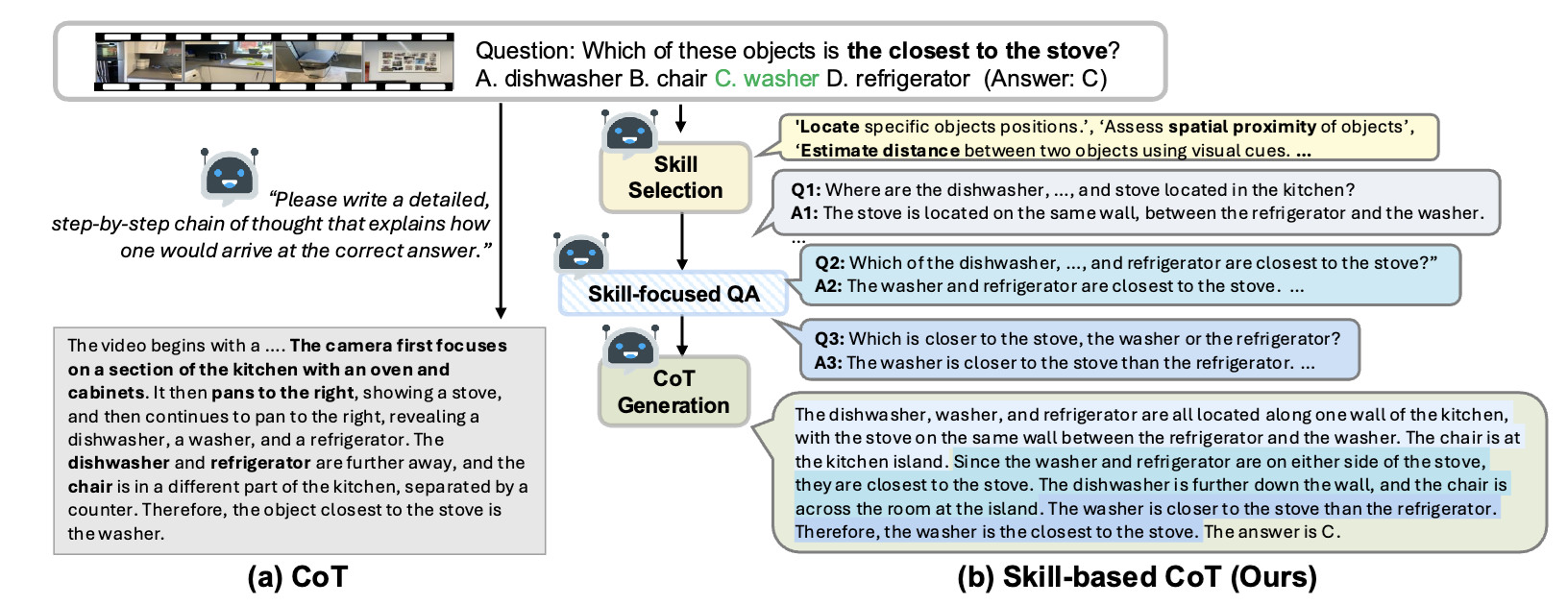
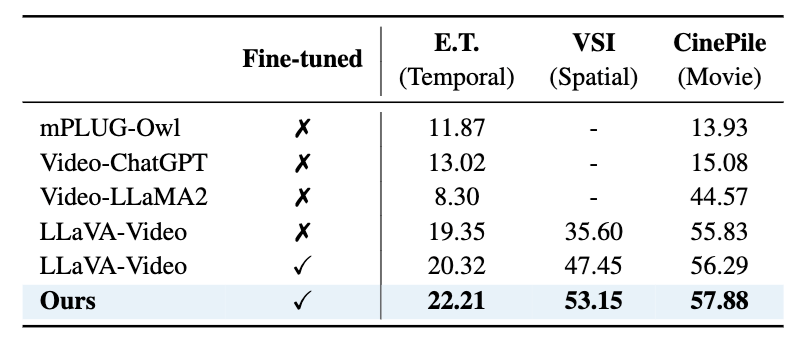
Motivation: Video datasets require different reasoning skills
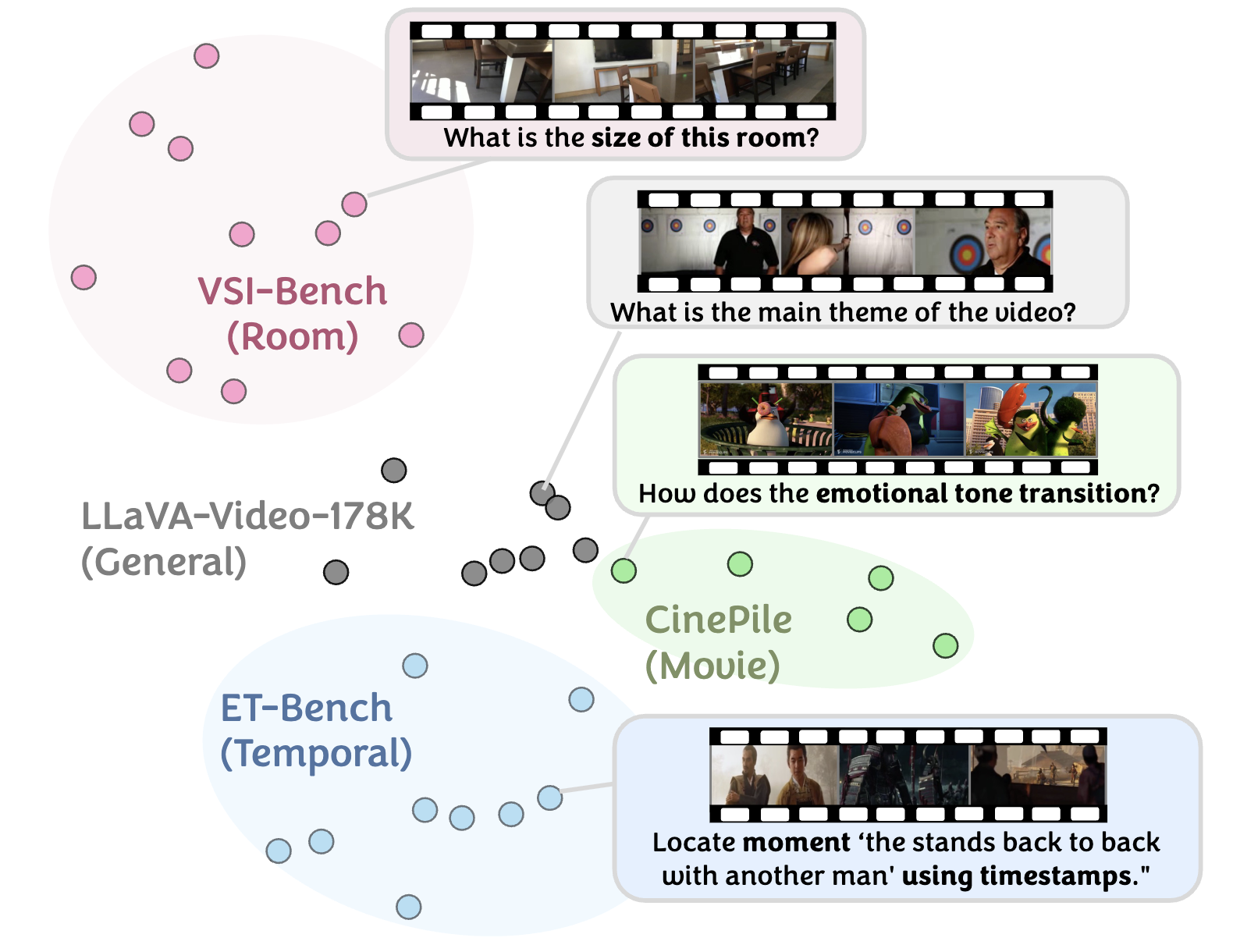
This t-SNE plot visualizes the relative embedding distances of input questions across various video datasets. Questions from the same dataset tend to form tight clusters, reflecting shared domains or required skills. For instance, models pretrained on general datasets like LLaVA-Video-178K (Zhang et al., 2024) often fall short in capturing the nuanced narrative understanding required in datasets like CinePile (Rawal et al., 2024), highlighting the importance of adaptation to unfamiliar domains or specialized tasks.